On Hierarchical Assembly Graphs and component IDs
The OpenCascade kernel contains the XDE framework whose name is transliterated as eXtended Data Exchange. While initially that framework served for data interoperability (with focus on STEP format), XDE appeared to become a not-so-bad tool for representation of assemblies in general. Let's speak a bit about XDE as this package is definitely something to be aware of, especially, if you are Ok with having some OCAF in your software architecture. We will start with a more in-depth look at how to represent CAD assemblies programmatically. A good program starts with a good idea, i.e., a clear and adequate formal representation of a problem to solve. A good formalism for assemblies should capture their following properties:
- Hierarchical structure. Intuitively, an assembly is a hierarchy of components. Each parent-child link represents a "part-of" relation between the components. Actually, different interpretations of parent-child relationship exist, but we will stick to this "part-of" semantics because it is evident and widely used.
- Instancing. The assembly structure should allow for instancing. For example, a single bolt should not be deeply copied when it is inserted many times in a digital model of some mechanism. Instead, we should have a single geometric model for a bolt, and as many instances of it as many occurrences it has. An instance is technically a reference to the unique geometric model supplied with a certain transformation matrix. If the instancing is broken or not supported by an assembly structure, we will have a significant memory overhead and likely less efficient engineering workflows. What applies to a single bolt should also work for a bolt with a nut, i.e., the instancing mechanism should make no difference whether you reference a part or a subassembly. Picture a car chassis. To design an assembly of a chassis, you will have to replicate the structure of a single wheel with its tire, disk, brakes, etc. Here it is highly recommended to avoid deep copying of geometry and reuse the available components as much as possible. Such reused components are called Prototypes in our local jargon.
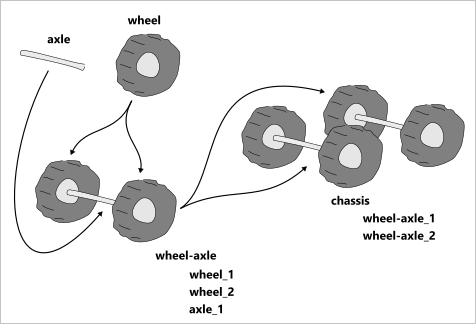 |
Car chassis assembled from two unique parts (wheel and axle). Instancing relationship is shown with arrows. All entities where arrows start are the Prototypes. These entities are not shown in the 3D scene directly. |
There is a useful formalism which captures the properties mentioned above. It is a Hierarchical Assembly Graph (HAG). The nodes of this graph represent the assembly components, and the arcs represent the "part-of" relations. HAG is essentially a directed graph without loops. A comprehensive overview of HAG with a valuable discussion of instancing can be found in the paper by A. Rappoport [A. Rappoport, A scheme for single instance representation in hierarchical assembly graphs, in: B. Falcidieno, T. L. Kunii (Eds.), Modeling in Computer Graphics, Springer Berlin Heidelberg, Berlin, Heidelberg, 1993, pp. 213–223].
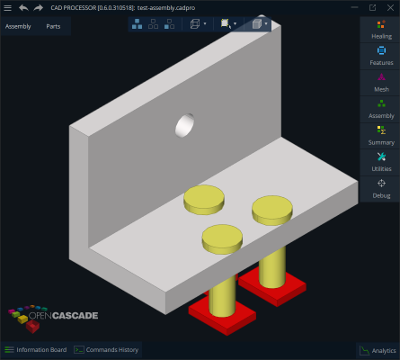 |
Simple assembly. |
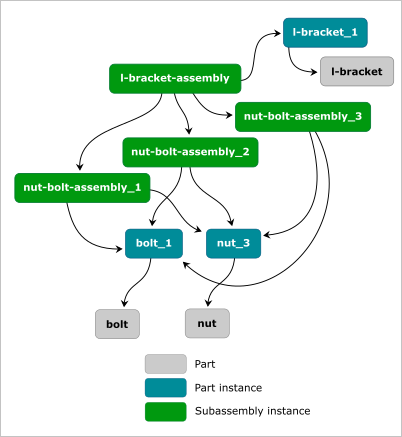 |
Hierarchical Assembly Graph for a simple assembly shown in the figure above. |
The programmatic realization of a HAG model is not as easy as it might appear at first glance. There are at least the following questions you should ask yourself before you go ahead with one or another data structure:
- Is your assembly a read-only object? I.e., are you going to modify the structure or just to read the existing (once created) hierarchy?
- How about filtering? Are questions like "give me all blue parts" of interest for you? If yes, probably, you would need some query language to drive filtering in a declarative fashion (i.e., explain WHAT you need, not HOW to do that). Notice that C++, C#, etc. are all imperative languages, so they will not give a freedom of custom queries out of the box.
- What is the typical size of your assembly? Is it something around 10-100 unique parts or more like thousands and even millions of parts?
- Which API do you need from an assembly engine? E.g., should it support merging components, drag & drop, grabbing instances into parts, etc.? It is a good idea to sit down for an hour and reflect on the demanded API.
Depending on your application domain, you will likely have other questions in mind. However, the cornerstone here is the technology. Not everybody wants to start an assembly structure from scratch because that sort of design is going to be very time-consuming. You will need to elaborate your assembly structure carefully to avoid spending hours on its further maintenance and redesign. Here are some technologies which might be of some help:
- OCAF/XDE. Do not merely deny this just because OCAF is a bit horrible and not exhaustively documented. It works. We use OCAF-based representation in our CAD Processor software, and it appears that OCAF is a workhorse which saved us tons of efforts.
- Relational databases such as SQLite, MySQL, PostgreSQL, etc. Be ready to implement the hierarchy of components together with instancing by yourself. Also, services like Undo/Redo will not be readily available. As an advantage, you obtain declarative queries, consistency ensured by the database engine (think of foreign keys), and an essentially collaborative environment (thanks to the client-server architecture).
- Hierarchical databases including no-SQL engines such as MongoDB.
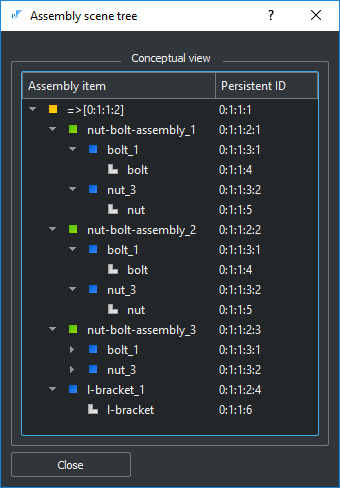 |
Scene tree which is a dual representation of a HAG. |
Regardless of technology, some peculiarities are originating from the HAG concept itself. One of the main questions is how to identify a single occurrence of a part in an assembly given that it has no dedicated graph entity (neither arc nor vertex).
One solution is to expand the graph into a tree (also called a "scene tree") by iterating it in the depth-first order. Having the scene tree as a main data container, you will be able to trace each occurrence of each Prototype. However, if choose XDE, it will be not easy to expand the underlying OCAF document from its graph representation into a tree. Also, you may desire to keep the graph explicitly as what really comes from a STEP file for an assembly is not a tree but a graph. For a HAG, a unique identifier of an assembly component is the path to this component in the graph. Here is the example of such an identifier:
0:1:1:1/0:1:1:1:1/0:1:1:2:2
The elements like "0:1:1:1" are the OCAF-stylish identifiers of the assembly components. These components are separated by "/" to make a path. Once you understand the composite nature of an object identifier in HAG, it is time to think how to represent such IDs programmatically. It may seem that the structures like std::vector<std::string> are well suited for such composite IDs. At least such structures look nice. Well, at least they look better than std::string alone. Well... Not exactly.
The reason for this blog post was actually a discovery that a primitive string ID is much better than a complex tuple of strings. Well, quite often we prefer complicated solutions because they are more simple to code. Sometimes they also look more "professional." In the example above, you may prefer a vector structure to emphasize that your identifier is
- Ordered,
- Well-structured.
However, there are more subtle things to reflect on. One particular problem we have been struggling with is the poor performance of data access for large assemblies. Because these complex identifiers are often used as keys in hash tables, it is necessary to provide an efficient way of computing hash codes. The hash code can be calculated relatively fast for the string values, while it is significantly less efficient for vectors. How would you calculate a hash code for a vector? Our solution was to concatenate all elements into a single string and then calculate the hash code for the final string. But stop! Dynamically growing vector means heap allocations which are known to beget the performance hotspots. Simple string representation for a complex identifier works better than a more structured entity because it is (almost) a primitive type whose hashing does not require allocations.
To conclude, be careful with the data structures you choose for driving your CAD assemblies. A bad data structure will avenge you for not investing enough time and brain power at the early stage of software design. Watch yourself when do coding ;)