Алгоритмическое дифференцирование в геометрических ядрах
«Do not write reusable code, write rewritable code». Istvan Csanady — the founder of Shapr3D modeler.
"A common disease in the software industry is 'software trashing', i.e., when one employee leaves the company his code gets trashed because nobody understands it, hence maintenance becomes impossible (L. Piegl and W. Tiller. The NURBS Book. p. 594).
Введение
На конференции ECCOMAS 2016 (Греция) был представлен замечательный результат. Ядро OpenCascade с открытым исходным кодом удалось скомпоновать с известной в узких кругах библиотекой ADOL-C. В результате в OpenCascade стали доступны точные производные по параметрам проектирования, которые называются sensitives (сенситивы, то есть показатели чувствительности модели к изменению ее параметров). Для чего это нужно? Опираясь на публикацию, послужившую поводом к данной заметке, приведем пример. Авторы рассматривают U-образный канал охлаждения турбины, состоящий из двух прямолинейных участков и циркулярного сочленения, как показано на рисунке.
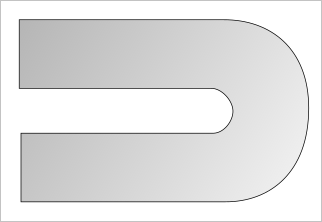
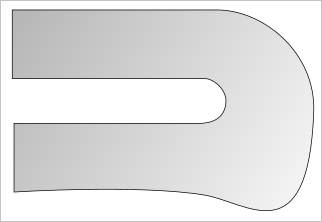
Модель строится методом скиннинга, о котором мы уже говорили ранее. Идея заключается в том, чтобы найти оптимальную форму контура охлаждения, имея в виду, что U-образная геометрия оптимальной не является из-за больших потерь давления. Поток как бы «заносит» на повороте, в результате чего он сталкивается со стенками канала, образуя вихри. На самом деле, оптимальной является примерно такая форма (нарисовано от руки, чтобы передать идею):
Но как получить этот результат численно? Метод следующий. Моделируем воздуховод при помощи CAD-движка, назначаем параметры формы, которые можно менять и запускаем метод оптимизации. Целевой функцией, подлежащей минимизации, является потеря давления в зависимости от параметров проектирования. Если мы способны подсчитать градиент данной функции, то нетрудно реализовать простейший метод градиентного спуска, который, управляя формой изделия, будет медленно, но верно сходиться к оптимальному решению. Именно для подсчета градиента нам нужны производные геометрии по параметрам проектирования.
Сделав это небольшое введение и, надеюсь, заинтересовав читателя, мы отсылаем его к чтению указанной статьи, а также всего комплекса доступных материалов по теме. Здесь же, оставаясь верными чистой геометрии, мы поговорим чуть более подробно об интеграции алгоритмического дифференцирования в геометрические ядра. Будем для простоты называть такую интеграцию дифференцированием. Итак, как поженить OpenCascade и ADOL-C?
Инъекция точных производных
Мы говорим исключительно о библиотеке ADOL-C, так как именно с нею был проведен изложенный в докладе эксперимент. Цель интеграции состоит в том, чтобы имплантировать специфический тип переменной в ядро моделирования. На словах все довольно просто: нужно подменить тип double на так называемый АКТИВНЫЙ тип adouble, который является носителем точных производных. За подробностями вы можете обратиться на сайт сообщества алгоритмического дифференцирования.
С точки зрения чисто технической реализации такой интеграции, выделим следующие способы дифференцирования:
- Дублирование кода ядра с заменой пассивного типа активным.
- Использование шаблонов с параметром типа.
- Глобальное переопределение типа (typedef).
Можно сказать, что первые два способа синонимичны, так как компилятор в любом случае будет использовать разные экземпляры кода для дифференцируемой и недифференцируемой версий алгоритма. Есть ли среди указанных способов наименее интрузивный?
Увы, следует проститься с задумкой дифференцировать библиотеку ВСЮ СРАЗУ. Разумное алгоритмическое дифференцирование начинается с выделения тех алгоритмов и структур данных, которые ДОСТАТОЧНЫ для решения ваших прикладных задач. После этого соответствующие алгоритмы и структуры данных должны быть приведены в надлежащее состояние, например, переписаны с использованием механизма шаблонов С++. Такой подход существенно интрузивен, но он позволяет достичь максимальной гибкости при внедрении алгоритмического дифференцирования, оставаясь при этом изящным и легко поддерживаемым. Последнего не скажешь о подходе с переопределением типа. Его использование влечет бесконтрольную инъекцию активных типов данных повсюду в коде, что является не только неэффективным в смысле производительности и расходуемой памяти, но и попросту некорректным по отношению к тем частям экосистемы, которые не являются алгоритмами (например, средства отрисовки). Достоинство у данной методики ровно одно — она реализуется проще остальных.
Какую методику выбрать — дело ваше. Чаще всего код, подлежащий дифференцированию, уже существует. Его адаптация под механизм шаблонов может оказаться слишком дорогостоящим мероприятием, что приводит к неизбежному следованию по пути переопределения типов. Ситуация с алгоритмическим дифференцированием во многом подобна ситуации с параллелизмом. Если соответствующие механизмы не заложить с самого начала проектирования библиотеки, то сделать это оптимальным образом когда-нибудь потом оказывается слишком затратно. Если вы проектируете собственную инженерную библиотеку и хотите использовать в ней аппарат алгоритмического дифференцирования, подумайте над способом его интеграции заранее.
Дифференцирование ядра
Дифференцирование ядра OpenCascade сопряжено с трудностями. Беспечная замена типа double на активный тип adouble невозможна из-за возникающих ошибок на стадии компиляции и в рантайме. Перечислять досадные нюансы мы не будем, их много. Например, если вы любите применять такие операции, как memset() или memcpy(), вас скорее всего будут ждать сюрпризы. Теоретически, можно адаптировать исходные коды библиотеки так, чтобы все эти проблемы исчезли. Для этого тип adouble не следует использовать в сервисных модулях библиотеки, таких как визуализация или OCAF.
Однако сам факт «протаскивания» активного типа еще ничего не значит, и вот почему. Активная переменная типа adouble — это «двойной агент». Во-первых, как и всякая переменная, она является именованным носителем значения. Во-вторых, — и в этом состоит специфика — это накопитель производной. Корректность подсчета производной зависит, прежде всего, от ненарушения цепочки дифференцирования (chain rule). Критически важно правильно использовать тип adouble на каждом уровне рекурсии дифференцируемого алгоритма. Но как это проконтролировать? Успешность компиляции ничего не значит. Успешность прогонки нерегрессионной базы также ни о чем не говорит, ведь тестироваться будет только первая роль adouble как носителя значения с плавающей запятой. Нужны дополнительные тесты на корректность дифференцирования, свидетельствующие о том, правильно или нет имплантирована эта хрупкая «система кровообращения» производных в тело каждого алгоритма. Разрыв единственного «капилляра» приведет к неверно рассчитанной производной. Значение, которое вы получите, будет просто не то, без каких-либо кодов ошибки, выброса исключений и тому подобного. Объем работ, которые необходимо провести для полного и надежного дифференцирования OpenCascade, весьма существеннен.
Но отвлечемся от OpenCascade и посмотрим на проблематику шире. Какие требования следует предъявить к дифференцируемой библиотеке?
- Возможность быстрого переключения между дифференцируемой и недифференцируемой версиями.
- Достаточный набор алгоритмов, в тела которых интегрирована логика точного дифференцирования.
- Наличие системы верификации, гарантирующей корректность результатов дифференцирования.
Озвученные требования некоторым образом остужают пыл оператора, стремящегося получить очередную «серебряную пулю» путем тривиальной замены пассивного типа double на активный adouble. Такая замена требует кропотливой предварительной работы, и проще всего эту работу осуществлять на библиотеках, не являющихся такими «сверхмассивными черными дырами», как OpenCascade.
Немного ядерной метафизики
"The commonly used modelers ACIS and Parasolid were developed in the late 80s. Since then they've been forked and patched and tweaked, but there are few people who were there from the start and who are still active... We refer to some of these other modelers as the black hole. The people who know how the code works, they're gone." (press about the KCM modeling kernel from Kubotek).
Во избежание коллапса библиотеки в состояние черной дыры нужна культура ее разработки. Геометрическое ядро — это экосистема, акторами которой являются алгоритмы. Ценность ядра находится в прямой зависимости от количества и качества имеющихся в нем алгоритмов. С количеством все ясно: чем больше, тем лучше. Что же касается качества, то всякий алгоритм объективно оценивается по трем классическим критериям:
- Точность.
- Надежность.
- Эффективность.
Допустим, что вся ваша библиотека состоит из точных, надежных и эффективных алгоритмов. Вам повезло, причем повезло нереально, потому что в жизни так не бывает. В жизни алгоритмы лажают. Это относится и к точности, и к надежности, и к эффективности. Следовательно, алгоритмы требуют периодического обслуживания. Что для этого нужно?
- Знать КАК алгоритм устроен.
- Знать ПОЧЕМУ он устроен именно так.
- Знать контекст использования алгоритма, его взаимодействие с другими частями целого.
- ...
Ключевое слово здесь «ЗНАТЬ». За тысячи лет своего существования, человечество не придумало более надежного способа передачи знаний, чем письмо. Вывод: алгоритмы надо документировать. Причем делать это исчерпывающим образом, иначе ЗНАНИЕ об этих алгоритмах уйдет вместе с его разработчиками.
Главный этаж документации — это сам алгоритм. Код должен быть написан грамотно, то есть с соблюдением норм модульности, именования переменных (лучше всего делать это сообразно с документацией) и обязательными блоками комментариев, поясняющих дело. Важно уяснить, что комментарии не засоряют код, а оживляют его. Вообще сама возможность делать НЕСЛЕПЫЕ модификации в коде, то есть четко понимая его логику, — это признак живого кода. В противном случае код мертв. Когда масса мертвого кода становится критической, ядро превращается в «черную дыру». Осмелимся заявить, что алгоритмы нередко пишутся мертворожденными с самого начала. Для этого программистам достаточно нарушить принцип documentation-driven development и пренебречь комментированием кода. В таком алгоритме любая последующая модификация является в той или иной степени слепой, и нередко заводит в тупик. Чтобы найти выход, нужно увидеть картину в целом.
Нелегко судить о качестве ядер, с разработчиками которых ты не знаком. Однако есть некоторые красноречивые косвенные признаки, позволяющие судить о живости того или иного ядра. Например, библиотека SMLib скорее всего не является черной дырой, так как ее алгоритмический слой поддерживается библией всех времен и народов The NURBS Book. То же самое можно сказать о библиотеке C3D, в поддержку которой Н.Н. Голованов (главный человек по ядру) написал монографию «Геометрическое моделирование». Про гигантов ACIS и Parasolid ничего сказать нельзя, так как эти библиотеки ведут очень закрытую политику. OpenCascade, хотя и удостоился выше звания черной дыры, эволюционирует в светлую сторону. Это видно по нарастающей активности разработчиков ядра в плане документирования новых алгоритмов.
Итоги
Как обычно, дьявол скрывается в деталях. Имея даже элементарный принцип интеграции точного дифференцирования в существующий код, мы сталкиваемся с необходимостью существенной адаптации последнего. А как это сделать, не понимая принципов функционирования подопытных алгоритмов? Что ж, конференция ECCOMAS показала, что выход есть. Этот выход состоит в интрузивной замене пассивного типа активным, что вполне допустимо в мире открытых исходных кодов. Почему нет? Да, для экспериментов подобного рода в вашем распоряжении должен быть исходный код моделирующего движка. И здесь OpenCascade не оставляет шансов другим библиотекам. Действительно, при всем их растиражированном могуществе, есть нюанс. Они абсолютно закрыты.