Журналирование алгоритмов
Теперь, когда мы поговорили о тестировании вообще, давайте сфокусируемся на некоторых частностях. Речь пойдет об инструментах для реализации юнит-тестирования, а именно о такой полезной штуке как журналирование.
Верификация результатов
С точки зрения теста алгоритм является «черным ящиком» с определенными входом и выходом.

Тест «знает» правильный выход для наперед заданного входа и осуществляет непосредственную проверку на совпадение полученных данных с ожидаемыми. Этот очевидный принцип мы не собираемся подвергать сомнению. Но посмотрим более детально, что с чем сравнивается и как это делается.
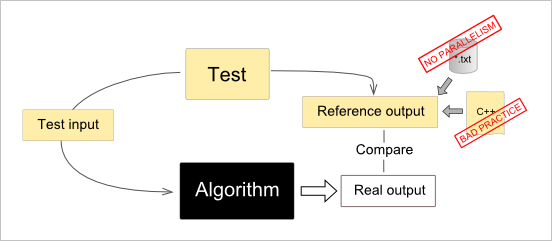
На картинке мы видим тест (Test), который подготавливает входные данные (Test input), запускает алгоритм и выполняет проверку полученного результата (Real output) на совпадение с заранее заготовленными данными. Эти данные (Reference output) считаются изначально корректными, что обеспечивается программистом или инженером, который точно знает, какой результат следует ожидать от алгоритма на том или ином входе. Ожидаемый выход «замораживается» сразу после окончания работ над алгоритмом. Обычно это делается либо путем прямого внесения ожидаемых данных в код теста (С++), либо записью этих результатов в файл для последующего построчного сравнения. Оба подхода имеют существенные недостатки:
- Кодирование ожидаемых результатов напрямую в исходнике C++ является смертным грехом. Во-первых, собственно логика тестирования оказывается погребенной под тоннами чисел, с которыми вы собираетесь сравнивать результат алгоритма. Во-вторых, чтобы поменять ожидаемые данные, придется компилировать тест заново. В-третьих, таковая замена нередко отнимает (по опыту) совершенно чудовищное количество времени. В-четвертых, это просто «не трю», т.е. стыдно, товарищи.
- Использование файлов для хранения результатов — это серьезный шаг вперед по сравнению с предыдущим подходом. Однако здесь есть нюанс, связанный с многопоточными алгоритмами. Этот нюанс реализуется в том случае, если выход алгоритма зависит от того, в каком порядке выполнялись потоки. Такое явление называется data races (гонки потоков) и часто свидетельствует о том, что в вашем алгоритме что-то не в порядке. Однако гонки могут быть и безопасными, если алгоритм выдает какое-то множество результатов, порядок следования элементов в котором не имеет значения (см. определение множества). Такие выходные данные, будучи записанными в файл, не совпадут с ожидаемыми результатами просто в силу стохастического порядка их возникновения. Построчное сравнение файлов становится невозможным.
Верификация выполнения
Волшебный подход TDD (Test-Driven Development) предполагает, что алгоритм пишется после того, как для него подготовлен соответствующий тестовый сценарий. Задача программиста таким образом сводится к тому, чтобы тест стал «зеленым». В мире инженерного ПО этот подход нередко звучит как издевательство, потому что заранее организовать логику теста на сложные алгоритмы бывает практически невозможно. Возвращаясь к нашей аллегории с экосистемой, подход TDD означает первоначальную подготовку среды, тогда как создание актора (субъекта среды) происходит уже пост-фактум. Этот метод не вполне отражает эволюционную парадигму развития ПО. Поэтому с практической точки зрения мне кажется удобнее трактовать TDD, как одновременное написание теста и алгоритма.
Наличие даже самого примитивного теста на этапе первичной реализации алгоритма позволяет запускать полезный код после каждого внесенного изменения и проверять промежуточные результаты запуска. Как это делается? Обычно в своем алгоритме мы просто пишем что-то вроде:
cout << "Intermediate value of variable A is " << A << endl;
Разумеется, все промежуточные выводы подобного рода придется удалить из окончательной версии алгоритма. Проблема только в том, что в эволюционной среде не бывает окончательных версий. Всякий раз, как изменения среды приводят к сбою в алгоритме, необходимо осуществлять дорогостоящую поддержку, то есть дебажить код. Обычно это приводит к тому, что удаленные инструкции cout (или им подобные) возникают вновь. В этом примитивном подходе к анализу поведения алгоритма есть серьезные минусы:
- Инструкции cout и им подобные могут вызываться из различных потоков. В этом случае построчное сравнение (если вы на него расчитываете) оказывается невозможным.
- Пребывая долгое время в закомментированном состоянии (или будучи подключаемыми в код с помощью макросов препроцессора), инструкции поточного вывода имеют свойство «протухать»: та переменная, значение которой мы пытаемся вывести в поток, уже могла быть удалена из кода.
- Инструкции cout не дают общего представления о том, как выполняется алгоритм. Обычно их вставляют только в проблемные места безо всякой системности. Вам нравится подобный код?
Если вам надоел этот старый как мир подход с поточным выводом, то читайте дальше. На помощь нам придет журналирование. Идея журналирования по сути ничем не отличается от привычного cout-подхода. Однако все обозначенные выше проблемы оказываются покрыты:
- Порядок записей в журнале не имеет значения. Даже если несколько потоков наперегонки кладут туда записи, сравнивать мы будем не построчный итоговый вывод, а накопленные журналы в целом.
- Код не протухнет, так как он компилируется всегда.
- Алгоритм не просто сбрасывает произвольные сообщения во временно открытый поток. Алгоритм ведет свой собственный лог, в котором записи имеют осмысленную семантику. Этот лог должен быть изначально исчерпывающим. Конечно, это требует соблюдения особенной культуры написания алгоритма: все значимые промежуточные результаты журналируются, и ничто не остается забытым.
Реализация журнала как структуры хранения данных не отнимет много времени. Например, можно использовать подход, представленный на картинке ниже:
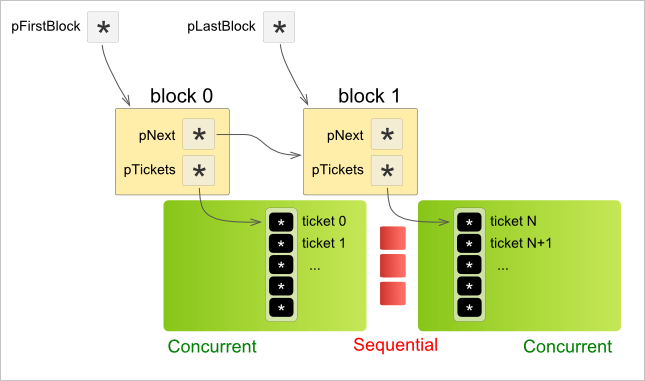
Здесь журнал организован как коллекция записей (Ticket). Каждый Ticket эквивалентен одной инструкции cout в коде алгоритма. Чтобы обеспечить возможность одновременного дампа из многопоточного кода, каждый Ticket ассоциируется с глобально инкрементируемым индексом, адресующим его во внутреннем массиве журнала. Индексы Ticket'ов могут быть получены при помощи атомарных операций ОС.
Чтобы не аллоцировать сразу слишком много памяти (мы не знаем, сколько раз алгоритм собирается делать cout), Ticket'ы организуются в блоки. Каждый блок допускает одновременный доступ из нескольких потоков. Однако создание нового блока сериализует выполнение алгоритма, так как в нашем случае блоки организованы в связанный список.
Имея журнал, устроенный подобным образом, мы можем работать с алгоритмом примерно так, как показано в следующем псевдокоде:
Journal* jrn = new Journal(); MyAlgo.Perform(jrn); jrn->Save(filename); delete jrn;
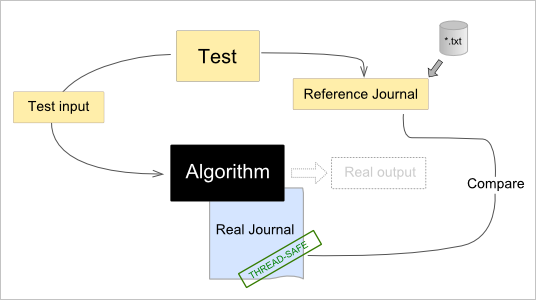
API наших алгоритмов должен быть спроектирован таким образом, чтобы принимать экземпляр журнала как опциональный входной параметр. В случае, если журнал не передается (указатель есть NULL), алгоритм работает в обычном режиме и промежуточный дамп не выполняется. Однако если алгоритму передать журнал, он начинает сбрасывать в него историю своего выполнения. Эту историю можно использовать для верификации в юнит-тестах. Например, давайте посмотрим на следующий псевдокод:
Journal* refJrn = new Journal(); refJrn->Restore(filename); refJrn->Compare(jrn);
Здесь заводится журнал, содержащий ожидаемые результаты, приходящие из файла. Затем этот журнал сравнивается с только что наполненным алгоритмическим журналом. Сравнение происходит по содержимому, т.е. порядок записей для нас не имеет значения. Таким образом, мы верифицируем не итоговые результаты выполнения алгоритма, а сам ход его выполнения. Концептуально эта схема представлена на рисунке ниже:
Итог
Верификация исполнения как альтернатива верификации результатов, конечно, более ресурсоемка. Однако в контексте юнит-тестирования тяжеловесность процедур нечасто является преградой. В силу своей природы верификация исполнения оказывается более исчерпывающей. Алгоритм, по сути, сам решает, какие промежуточные данные, возникающие в ходе его работы, имеет смысл проверять на корректность, т.к. проверяется ровно то, что было сброшено в журнал. Эта «интеллектуальность» алгоритма достигается путем осмысленного журналирования, которое, как подход, является не более чем дальнейшим развитием всем знакомой cout-мистерии.